Overcoming barriers to automatic parallelization
Parallelism
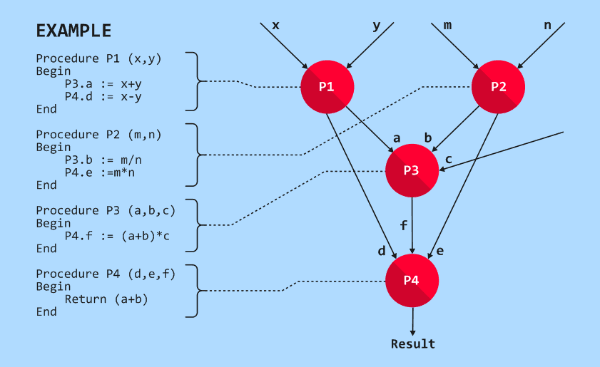
- Sciensys aims to disrupt the field of computing parallelism, developing systems dedicated to high performance computing and, achieve the required energy efficiency the Internet of Things (IoT) autonomous data processing systems require.
- Porting any program on a parallel architecture currently rests a full challenge. Sciensys has achieved a general solution to this problem by implementing a mix of data flow and control flow principles. This provides automatic parallelization during run time.
Development
News
April 2017 University of L’Aquila - Center of Excellence DEWS and Sciensys entered into partnership to implement and test Sciensys architecture on specific complex computations requiring intense parallelization. The tests showed Sciensys computation technique was >3.5x faster.
The results were published in Hipeac Info #50 (page 26).

Patents
Sciensys’ advanced technology is protected by various patent filings.

Key features
- Automatic parallelization at task level during runtime: any procedure can be automatically executed on any available executive unit of a multiprocessor system, as soon as required inputs are available.
- Multigrain parallelism. Coarse grain (on procedure level). Fine grain (on dataflow instruction level)
- Automatic parallelization on multicore processors during run time, based on a disruptive technology
- Increased performance; performance becomes a quasi-linear function of the number of the cores of the microprocessor
- Automatic allocation to any arbitrary number of processor cores coupled to the end user’s choice of any SMP processor
- Traditional programming Programmers can program in usual language, without consideration for a multi-core architecture
- Absence of cache memory without loss of performance
- Jump the "memory wall". Computing speed is limited only by the communication network
- Easy scaling
- Ability to work without OS
- Control Flow and Data Flow calculations support
Breakthroughs
The system operates upon two levels of concurrency
Coarse-grain, at the procedures level. The procedure can be performed automatically on any free processor, and the code that called it doesn’t wait for the procedure to return, but keeps on with the performance.
Fine-grain, at the level of special co-processor instructions. We call it Arithmetic Dataflow Processor (ADFP). This processor allows performing calculations when the data is available. This processor comprises associative storage, arithmetic device for operations on integers and real numbers, and a network controller to integrate multiple processors into a network.
ADFP is a kind of “active” memory since it can run calculation and the set of such processors can be considered as global active memory with CPU connecting to an array of processors, even if different CPUs have separate physical memory. This provides automatic parallelization on low level.
 Architecture based on the concept of computation upon data availability
Architecture based on the concept of computation upon data availability
 Calculations both in the instruction flow and data flow: hybrid architecture
Calculations both in the instruction flow and data flow: hybrid architecture
 Hardware concurrency of calculations at the level of arithmetic operators
Hardware concurrency of calculations at the level of arithmetic operators
Sciensys' architecture superiorities
Ability to reach GPUs performance while executing scalar operations
GPUs are single-instruction / multiple-data. Sciensys technique are multiple-instructions / multiple-data. A Sciensys co-processor can be used for universal calculations with unprecedented flexibility.
GPUs vs. our processor: with a given number of cores, a GPU and our system will have the same performances. Though they will be equal, a Sciensys co-processor can execute a wider variety of more significant applications.
A GPU operates only with vectors and Sciensys ‘ co-processor operates on scalar calculations and therefore can provide performances equivalent to GPU. We will enjoy having a great flexibility in comparison with GPUs to implement complex algorithms.

Added value of Sciensys’ hybrid architecture
Easiness to implement on FPGA board.
Minimum programmer’s work: Define the procedures to be run in parallel, chose the model of computation (data flow / control flow). In most cases, data flow calculations on level of operators will automatically be done by the compiler.
Flexibility
- Tuning / behavior of the system is easily controlled in the program code
- Modification - the system is easily configured via a graphical interface or VHDL-code
- Use of a variety of platforms - as a base, you can take any multiprocessor system, including not symmetrical systems
Scalability
- Arbitrary number of CPUs - depends only on the density of on-chip FPGA, PCB
- Multiple means of communication - may be hardware bus protocols, classical data transmission between computing devices and others
- Almost linear boost of performance with the addition of CPUs (boost is only limited by the level of possible program parallelization)
Applications
 Digital signal processing
Digital signal processing
 Matrix algebra
Matrix algebra
 Image processing
Image processing
 IoT (Internet of Things)
IoT (Internet of Things)
 Cyber-Physical Systems
Cyber-Physical Systems
 Medical imaging
Medical imaging
 Artificial intelligence
Artificial intelligence
 Image recognition
Image recognition
 Other applications requiring high speed of numeric calculation
Other applications requiring high speed of numeric calculation
Internet of Things (IoT) growth
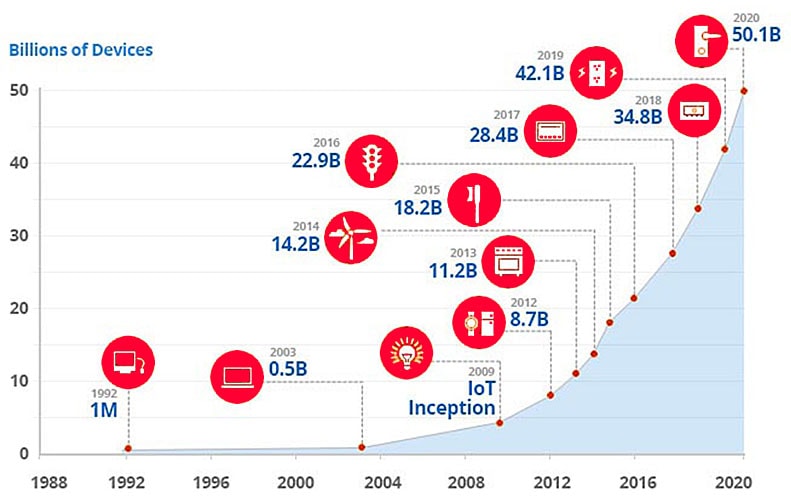
- For the past ten years, parallelism has become a much talked about topic. A new phenomenon, the Internet of Things (IoT), which will call for the introduction of significant computing power at the level of the elementary things (sensors and things that people will wear) along with very stringent energy consumption constraints. A huge energy efficiency gain for such information systems has to be reached. This kind of application requires a 1/100 to 1/1,000 processor power reduction.
- Parallelism is the unique solution in the middle run to meet this gain target as it allows replacing a major system working at the frequency f by N minor systems operating at the f/N frequency.
Company
Sciensys has elaborated a powerful disruptive technology in the field of automatic parallelization
- Sciensys is incorporated in France, with offices in central Paris.
- Sciensys has unique, patented computing technology geared to real time applications demanding intense computation to be run on multi-core processors.
- We have designed an original architecture – especially for dynamic applications – and a new processor generation. We aim to work with industrial companies to have them implement their complex applications through hardware integration on GPU, FPGA and multi-core standard market processors.

Sciensys is a member of the Embedded France Association
